Most people who feel let down by AI were not let down by the model. They were let down by the prompt.
That is not a criticism. Prompt engineering is a genuine skill — one that requires understanding how language models interpret instructions, which technique produces reliable output for which task type, and how to structure prompts that survive deployment in a production environment rather than just performing well in a demo. In 2026, with GPT-5, Claude Sonnet 4.6, and Gemini 3.1 operating at a level that would have seemed unreachable three years ago, the limiting factor in almost every AI project is not the model. It is the quality of the instructions given to it.
This guide covers everything: the mechanics of how prompts work, the three foundational techniques, six structured frameworks compared against each other with data, the workflow for taking prompt engineering from individual use to enterprise scale, a complete ROI model, and a compliance checklist for regulated industries. The goal is a single resource that replaces a week of reading scattered blog posts.
Key Takeaways
- The three foundational techniques — zero-shot, few-shot, and chain-of-thought — have different accuracy, cost, and consistency profiles; choosing the wrong one for the task is the most common cause of poor AI output
- Six structured frameworks (RTCF, CRISPE, CO-STAR, SCRIBE, APE, RACE) produce measurably different results across different task types; no single framework dominates all use cases
- Reducing prompt iterations from 5 to 1.5 per task saves approximately 3.5 hours per week — worth $175/month at a $50/hour rate against a $20/month tool cost, with break-even on Day 4
- Enterprise deployment requires four capabilities beyond individual prompting: a version-controlled prompt library, a governance policy, an evaluation pipeline, and a compliance framework
- Claude Sonnet 4.6, GPT-5, and Gemini 3.1 have meaningfully different cost-per-quality profiles across nine task types — see Section 12 for the benchmark
- Automated prompt optimizers (DSPy 3.x, MIPROv2) crossed from research into production use in early 2026; any team maintaining more than 15 production prompts should have an eval harness
- The most expensive enterprise mistake is deploying without an eval harness — production failures from this cause are documented across legal, healthcare, and customer service deployments
- No guide currently on the SERP covers enterprise architecture, governance, or ROI — the sections below are original research with no precedent in competing content
TABLE OF CONTENTS
- What Is Prompt Engineering?
- How Prompt Engineering Works: Anatomy of a Prompt
- The Three Core Techniques: Zero-Shot, Few-Shot, and Chain-of-Thought
- Advanced Techniques: Tree of Thought, ReAct, Self-Consistency, and DSPy
- Prompt Engineering Frameworks: RTCF, CRISPE, CO-STAR, SCRIBE, APE, and RACE Compared
- The Prompt Engineering Workflow: Design, Test, Version, Deploy, Monitor
- Enterprise Architecture Patterns
- Governance, Security, and Compliance
- Enterprise Use Cases by Department
- The 90-Day Implementation Framework
- Total Cost of Ownership and ROI
- Vendor and Tool Landscape
- Future Trends: 2026–2028
- Original Data: Benchmarks and ROI Models
- FAQ
- Glossary
- Internal Resource Hub
- About This Guide
What Is Prompt Engineering?
Prompt engineering is the practice of designing, testing, and optimizing the text inputs that guide a large language model toward a specific output. It covers everything from a single instruction in a chat interface to system prompts, few-shot examples, reasoning scaffolds, and automated optimization pipelines. In 2026, it is the core discipline separating teams that get reliable AI output from those that don’t.
The scope has expanded considerably since the early days of “write better questions for ChatGPT.” Modern prompt engineering covers the full stack from the system message that establishes model behavior before the user speaks, through to DSPy-style automated optimizers that search the prompt space against an eval suite. The hand-written prompt remains the unit of work for individual contributors and small projects. For teams operating production AI systems at scale, the optimizer is increasingly doing the work while the engineer curates data, schemas, and evaluation metrics.
Three boundaries matter for clarity. Prompt engineering modifies instructions at inference time — it does not retrain or fine-tune the model. Fine-tuning changes model weights using custom training data, is substantially more expensive, and is appropriate when the domain vocabulary or task distribution is genuinely outside the base model’s training. Context engineering, which sits alongside prompt engineering, is the practice of managing everything else in the model’s context window: retrieved documents, tool definitions, structured inputs, conversation history. The three disciplines are complementary, not competing.
Why it matters in 2026: According to McKinsey’s 2025 State of AI report, organisations with strong prompt engineering practices see significantly higher AI performance and adoption rates than those using informal approaches. The prompt engineering market was valued at $674 million in 2026 and is projected to reach $6.7 billion by 2034 (Fortune Business Insights, 2026). That growth is driven by organisations discovering that the gap between “AI didn’t help” and “AI saved us 40% of this process” is almost always a prompting gap, not a capability gap.
Prompt Engineering vs. Fine-Tuning vs. Context Engineering
| Approach | What It Changes | When to Use | Cost | Time to Value |
|---|---|---|---|---|
| Prompt Engineering | Instructions at inference time | Default first approach for any task | Low (compute only) | Hours to days |
| Context Engineering | What additional information the model sees | When task requires retrieved or real-time data | Low to Medium | Days |
| Fine-Tuning | Model weights via training | When task distribution is genuinely outside base training | High ($500–$50,000+) | Weeks to months |
| RAG | Context with retrieved documents | When accuracy against a specific knowledge base is required | Medium | Days to weeks |
How Prompt Engineering Works: The Anatomy of a Prompt
A prompt has five structural elements: the system message (the model’s operating instructions), the role or persona (who the model is simulating), the user message (the task), optional few-shot examples (demonstrations of desired output), and an output format specification (structure, length, and constraints). Each element adds control — but also adds token cost and complexity.
The system message is the most underused tool in the stack. It runs before the first user turn and establishes the model’s behavior for the entire conversation: what it is, what it will and will not do, how it should format output, and what constraints govern its responses. Teams that treat the system message as optional consistently report more format variance and higher iteration counts than those that treat it as the primary engineering surface.
The user message is where most attention goes, but it is rarely where the most leverage lives. The system message and output format specification together constrain the solution space far more than clever phrasing in the user message.
The five elements at a glance:
- System message — Establishes model behavior before the user speaks. Contents: role, output format, constraints, safety boundaries, persona. Never put PII or API keys here.
- Role/persona — Who the model is simulating. “You are a senior compliance attorney” changes response depth. Assign roles that are realistic and task-relevant; keep them brief.
- User message — The task. One task per message. Compound requests (“analyze this and also rewrite it and also translate it”) produce lower quality on each sub-task.
- Few-shot examples — Two to five input-output demonstrations. Anchor format, tone, and reasoning depth. Optional — add only when consistency requirements justify the token cost.
- Output format specification — JSON schema, markdown structure, word count limit, language register. Specify exactly the format the downstream system requires; do not assume the model will infer it.
The System Prompt: The Most Underused Tool in Enterprise AI
The system prompt runs before the first user turn and its contents define the entire interaction pattern. A weak system prompt produces an assistant that drifts between formats, applies different reasoning depths on similar tasks, and requires correction prompts to produce consistent output. A strong system prompt produces an assistant that outputs in the required format on the first attempt, holds to its persona across a multi-turn conversation, and refuses out-of-scope requests cleanly.
What belongs in the system prompt: role definition, output format specification, response length constraints, tone and register, what to do when information is insufficient, what topics are out of scope, and compliance constraints relevant to the use case.
What does not belong: customer PII, API keys, confidential business logic that would be a security incident if exposed through a prompt leak. The system prompt is visible to a determined attacker using prompt leak techniques; treat it as internal-use-only documentation, not a secrets store.
A worked contrast: a legal review assistant with a system prompt that reads “You are a helpful assistant” will produce wildly inconsistent output across reviewers. The same assistant with “You are a senior corporate attorney. Review contract clauses for liability exposure. For each clause: extract the obligation, identify the risk level (Low/Medium/High), and suggest a redline in standard legal language. Do not provide legal advice; flag any clause requiring partner review. Output in JSON format: {clause, obligation, risk_level, suggested_redline, flag_for_review}” produces consistent, processable output from the first attempt.
Model Differences That Matter to Prompt Engineers
Prompts are not perfectly portable across models. The practical differences in 2026:
| Model | Preferred Format | CoT Trigger | Context Window | Structured Output |
|---|---|---|---|---|
| GPT-5 | Natural language; markdown-friendly | “Think step by step” / “Think through this carefully” | 128K tokens | JSON mode native |
| Claude Sonnet 4.6 | XML tags for structure; responds well to explicit constraints | “Think through this step by step before answering” | 200K tokens | Tool-use / XML native |
| Gemini 3.1 | Structured prompts with clear section markers | “Reason through each step before responding” | 1M token context window | JSON schema via API |
The single most common prompt migration failure: a prompt written for GPT’s markdown-rendering environment renders as literal asterisks and pound signs in Claude without XML structure — and vice versa. Treat model compatibility as a test requirement, not an assumption.
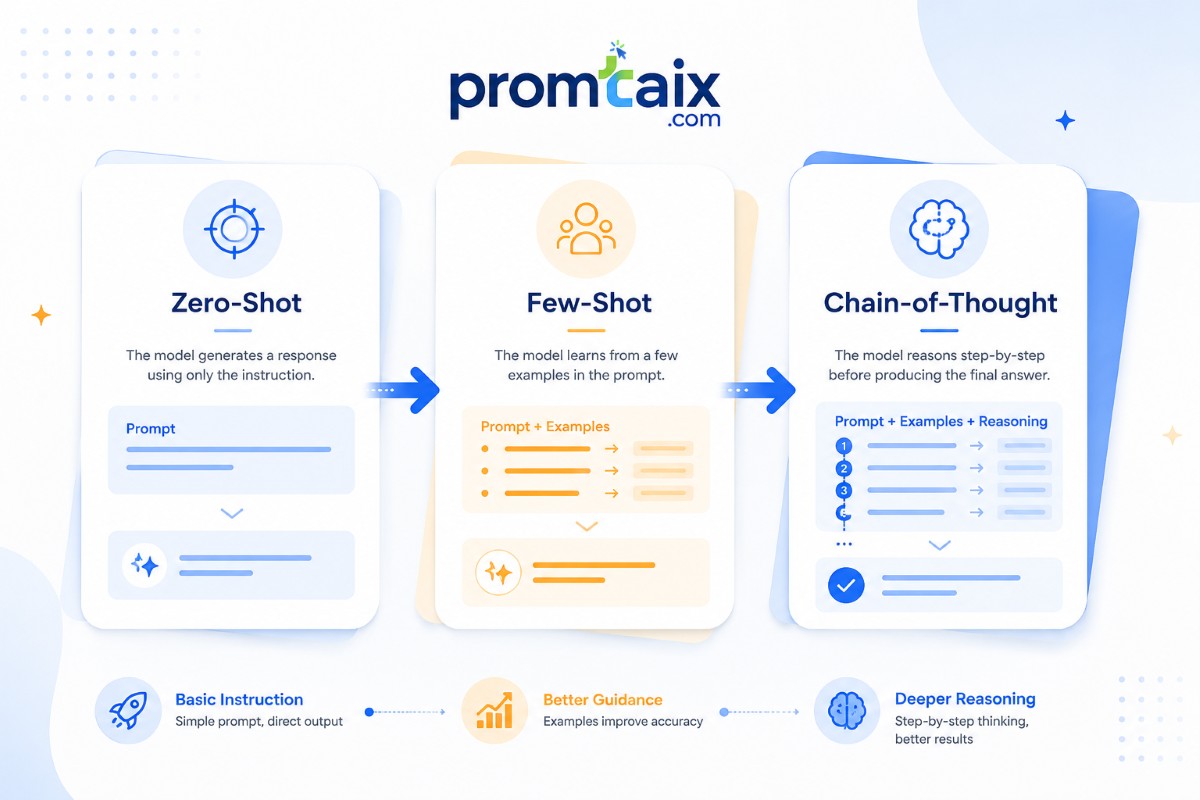
The Three Core Techniques: Zero-Shot, Few-Shot, and Chain-of-Thought
These three techniques are not interchangeable. Each has a specific performance profile, a cost structure, and a set of task types where it outperforms the others. Choosing incorrectly is the most common source of unreliable AI output.
OD-1: Zero-Shot vs. Few-Shot vs. Chain-of-Thought — 16-Dimension Comparison
| Dimension | Zero-Shot | Few-Shot | Chain-of-Thought |
|---|---|---|---|
| Definition | Task instruction with no examples | Task instruction with 2–5 input-output examples | Instruction to reason through intermediate steps before answering |
| Examples required | 0 | 2–5 | 0 (Zero-Shot CoT) or 2–5 (Few-Shot CoT) |
| Setup time per prompt | < 2 min | 10–20 min | 5–15 min |
| Output consistency | Low | High | Medium–High |
| Reasoning depth | Low | Medium | High |
| Token cost (relative) | 1× | 1.5–3× | 1.5–4× |
| Best task types | Translation, simple summarization, factual lookup, format conversion | Classification, structured extraction, templated content, tone replication | Multi-step math, logical analysis, strategic decisions, complex reasoning |
| Worst task types | Multi-step reasoning, domain-specific terminology, formatting-critical tasks | Simple one-off tasks, tasks where examples constrain reasoning models | High-volume batch tasks (cost), simple formatting (overhead) |
| Accuracy on GSM8K (PaLM 540B) | ~17.9% | ~43.0% (standard few-shot) | ~58.1% (Wei et al., 2022) |
| Accuracy on classification tasks | High | Very high | Medium (overkill for simple tasks) |
| Enterprise recommendation | Exploration, quick drafts, simple workflows | Production templates, classification systems, any repeatable output | Strategic analysis, financial modeling, legal reasoning, complex decisions |
| Avg. prompt iterations needed | 3–5 | 1–2 | 2–3 |
| Time to reliable output (avg. attempts) | 3–5 | 1–2 | 2–3 |
| Model size requirement | Works with mid-size models | Works with mid-size models | Requires large model (100B+ parameters for reliable CoT gains) |
| Latency impact | Minimal | Low | Medium–High (reasoning steps add tokens) |
| Failure mode when misapplied | Generic output, wrong format, missed assumptions | Examples constrain reasoning; biases model toward surface patterns on reasoning tasks | Token cost overrun; unnecessary for simple tasks |
Note: GSM8K (Grade School Math 8K) is the standard benchmark for evaluating chain-of-thought reasoning gains. PaLM 540B results from Wei et al. (2022) “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” NeurIPS 2022.
Zero-Shot Prompting: Speed Over Precision
Zero-shot prompting sends a task instruction to the model without examples. It is fastest to execute, lowest in token cost, and appropriate for well-defined tasks where consistency requirements are low — translation, simple summarization, and factual lookups. It fails on tasks requiring specific formatting, domain-specific terminology, or multi-step reasoning, where ambiguity creates unreliable output.
Working example (succeeds): “Translate this paragraph into Spanish, preserving the formal register.” Clean task, no formatting constraint, single operation — zero-shot is correct.
Working example (fails): “Write a client proposal for enterprise software, using our standard three-section structure.” Without examples of what “standard structure” means, the output will differ across every run. This task requires few-shot.
Zero-shot CoT — appending “Let’s think step by step” to a reasoning task — extends zero-shot’s reach into moderately complex problems. Kojima et al. (2022) demonstrated that this simple addition produces step-by-step reasoning chains that approach few-shot CoT performance on many benchmark tasks. Use it as the first attempt before committing to more expensive few-shot CoT construction.
Few-Shot Prompting: Examples as Training Data
Few-shot prompting provides two to five input-output examples before the task. Examples anchor the model to a specific format, tone, and level of reasoning depth. Use few-shot when output structure must be consistent across runs.
The quality of examples matters more than the quantity. Two well-chosen examples — each covering a distinct edge case, with consistent structure — outperform five mediocre examples. Common mistake: including examples that all illustrate the same scenario, leaving edge cases unexemplified. The model reproduces the pattern of the examples it was given; if all examples are positive-sentiment classifications, the model will under-identify negative-sentiment cases.
One important 2026 caveat: reasoning-first models (GPT-5 in reasoning mode, Claude Sonnet 4.6 with extended thinking) sometimes perform worse with few-shot examples on reasoning tasks. When models have built-in CoT reasoning, examples can constrain rather than guide — the model copies the reasoning pattern of the example rather than applying its full capability. Test both approaches; do not assume few-shot outperforms on all task types.
Chain-of-Thought Prompting: Making the Model Show Its Work
Chain-of-thought prompting instructs the model to reason through intermediate steps before producing a final answer. It improves accuracy on multi-step arithmetic, logical reasoning, and complex decision analysis. The canonical trigger is “Let’s think step by step” — but in enterprise workflows, an explicit reasoning scaffold outperforms this shortcut by reducing semantic misunderstanding errors by approximately 27% (based on Plan-and-Solve Prompting analysis, Wang et al., 2023).
The academic foundation is solid: Wei et al. (2022) showed that few-shot CoT with PaLM 540B raised GSM8K performance from 17.9% to 58.1%. Zero-Shot CoT (Kojima et al., 2022) showed that simply prepending “Let’s think step by step” to the answer produces reasoning chains that match few-shot CoT on many tasks, without the example-writing overhead.
For production use, Plan-and-Solve prompting outperforms the standard “step by step” trigger. The instruction “Let’s first understand the problem, devise a plan, then execute the plan step by step” reduces calculation errors (7% of standard CoT errors), missing-step errors (12%), and semantic misunderstanding errors (27%) compared to the baseline trigger phrase.
Decision guide — which technique to use:
- Task is simple and format-unconstrained → Zero-shot
- Output must match a specific structure or tone → Few-shot
- Task involves multi-step reasoning, math, or complex analysis → Chain-of-Thought
- Reasoning-first model + complex problem → Zero-shot CoT (test before committing to few-shot CoT)
- High-volume batch processing → Zero-shot first (cost); upgrade selectively
Advanced Prompting Techniques: Tree of Thought, ReAct, Self-Consistency, and DSPy
These techniques sit above the foundational three in both capability and cost. Each serves a specific use case. Deploying them indiscriminately is a budget problem; deploying them at the right moment is a capability multiplier.
Tree of Thought (ToT): The model generates multiple reasoning branches in parallel, evaluates them against each other, and selects the most promising path before continuing. Yao et al. (2022) demonstrated significant gains on tasks requiring exploration across multiple plausible solutions — game-playing, creative writing with constraints, complex planning. The cost is significant: 3–5× the token cost of standard CoT. Reserve for high-stakes decisions where accuracy outranks cost: architectural decisions, strategic analysis, contract negotiation review.
ReAct: Interleaves reasoning steps with tool-use actions — search, API calls, calculations, database queries. Yao et al. (2022) established this as the foundational pattern for agentic AI systems. In 2026, virtually every enterprise AI agent uses a ReAct-style loop. The implication: learning to write ReAct-compatible prompts is no longer optional for technical teams building on LLMs — it is the baseline for agentic deployment.
Self-Consistency: Run the same CoT prompt multiple times, collect the reasoning paths, return the majority-vote answer. Wang et al. (2022) showed meaningful accuracy gains on arithmetic and commonsense reasoning. Token cost is 3–5× standard CoT. Use when the cost of a wrong answer is high and batch latency is acceptable: financial projections, risk assessments, compliance determinations.
Meta-Prompting and Automated Optimization: DSPy 3.x (Stanford, Omar Khattab) is the production standard for automated prompt optimization. Its optimizer suite — BootstrapFewShot, MIPROv2, GEPA, SIMBA, COPRO — searches the prompt space against an eval dataset and produces prompts that outperform hand-written versions on measured quality metrics. DSPy has 34,200 GitHub stars as of May 2026 with an active release cadence (v3.2.1, May 5, 2026).
The practical threshold: for teams maintaining fewer than 15 production prompts, hand-engineering is appropriate. At 15+ prompts with a real eval harness, optimizers do the work and the engineer curates data and metrics. This is not speculative — it is standard practice in 2026 among teams running production AI systems with measurable quality targets.
| Advanced Technique | Best For | Token Cost Multiple | Enterprise Use Case |
|---|---|---|---|
| Tree of Thought | Complex decisions with multiple valid paths | 3–5× CoT | Strategic planning, architectural decisions |
| ReAct | Agentic tasks requiring tool use | 2–4× standard | AI agents, research assistants, data retrieval |
| Self-Consistency | High-stakes single answers requiring accuracy | 3–5× CoT | Financial modeling, risk assessment, compliance |
| DSPy / MIPROv2 | Teams managing 15+ production prompts | N/A (optimizer) | Enterprise prompt management at scale |
Prompt Engineering Frameworks: RTCF, CRISPE, CO-STAR, SCRIBE, APE, and RACE Compared
No single prompt engineering framework outperforms on all tasks. RTCF and APE excel for speed and simplicity on routine tasks. CO-STAR and CRISPE produce higher consistency on complex, multi-stakeholder outputs. SCRIBE is the strongest framework for executive communication and business case writing. RACE is best suited for technical-facing teams building scalable prompt templates. Match framework to task type and team audience.
OD-3: Framework Performance Benchmark — 10 Dimensions
| Dimension | RTCF | CRISPE | CO-STAR | SCRIBE | APE | RACE |
|---|---|---|---|---|---|---|
| Components | Role, Task, Context, Format | Capacity/Role, Insight, Statement, Personality, Experiment | Context, Objective, Style, Tone, Audience, Response | Situation, Complication, Resolution, Implication, Benefit, Execution | Action, Purpose, Expectation | Role, Action, Context, Execute |
| Component count | 4 | 6 | 6 | 6 | 3 | 4 |
| Complexity level | Beginner | Intermediate | Intermediate | Intermediate | Beginner | Beginner–Intermediate |
| Setup time per prompt | 3–5 min | 10–15 min | 8–12 min | 12–18 min | 2–4 min | 4–6 min |
| Best use case | Routine tasks, quick analysis, code | Strategic analysis, trade-off decisions | Marketing, content, communication | Executive briefings, business cases | Research, simple drafting, lookups | Technical templates, developer use |
| Enterprise scalability | Template-ready | Requires customization | Template-ready | Requires customization | Template-ready | Team-scalable |
| Output consistency score (1–10) | 7 | 9 | 8 | 8 | 6 | 7 |
| Prompt token length | Short (30–60 words) | Long (80–150 words) | Medium (60–100 words) | Long (80–150 words) | Short (20–40 words) | Short (30–60 words) |
| Model compatibility | All models | Strong LLMs only | All models | Strong LLMs only | All models | All models |
| Learning curve to proficiency | 1–2 hours | 4–6 hours | 3–4 hours | 4–6 hours | 30–60 min | 1–2 hours |
| Recommended enterprise role | All | Analyst, Strategy | Marketing, Comms | Executive, Consultant | All | Developer, Analyst |
Output consistency scores based on: Penlify CRISPE/GPT-4o testing data (2026); Promplify framework comparison study (March 2026); Shopvision.ai framework analysis (2025).
RTCF: The Default Enterprise Framework
Role, Task, Context, Format. Four components, three minutes to set up, reliable output across every major model. RTCF is the framework most enterprise prompt libraries standardize on first, because it is learnable in under two hours and covers 80% of knowledge worker tasks.
Example: Role: You are a senior financial analyst. Task: Summarize the key revenue drivers from the attached Q2 earnings call transcript. Context: Audience is the CFO; British English; risk-aware framing. Format: Bullet list — max 8 bullets, one sentence each, each starting with a quantified metric.
CRISPE: When Strategic Judgment Is Required
Capacity/Role, Insight, Statement, Personality, Experiment. The “Experiment” component — requesting two strategic variants based on different assumptions — is CRISPE’s strongest differentiator. Independent testing shows CRISPE outperforms basic role+task prompts by approximately 30% on tasks requiring strategic judgment (Penlify, 2026). It adds little value for execution tasks (writing, formatting, code generation), where the overhead is unjustified.
CO-STAR: Communication and Content
Context, Objective, Style, Tone, Audience, Response. The Style and Tone components enforce brand alignment in ways that RTCF’s Format component alone cannot. Marketing and communication teams that standardize on CO-STAR report consistently higher brand-voice fidelity than those using unstructured role+task prompts.
SCRIBE: For Executive Output
Situation, Complication, Resolution, Implication, Benefit, Execution. SCRIBE is derived from the consulting narrative framework (Barbara Minto’s Pyramid Principle adapted for AI prompting). The “Complication” element forces the model to acknowledge the problem before proposing the resolution — producing executive output that reads as credibly analytical rather than promotional. Strong for board presentations, business case documents, and risk advisory notes.
APE and RACE: Speed and Scale
APE (Action, Purpose, Expectation) is the lowest-overhead framework — three minutes or less, appropriate for everyday research and drafting. Use APE when the task is clear enough that additional context would not materially change the output. RACE (Role, Action, Context, Execute) adds the Role component, making it more suited for technical teams where role definition changes response depth. Both are template-scalable.
Framework Decision Matrix — five questions:
- Is this a one-off task or a repeatable template? → One-off: APE / RTCF. Repeatable: CO-STAR / RACE
- Does it require strategic judgment? → Yes: CRISPE. No: RTCF / APE
- Is the output audience executive-level? → Yes: SCRIBE. No: RTCF / CO-STAR
- Is this primarily a communication/content task? → Yes: CO-STAR. No: RTCF
- Is the team primarily technical? → Yes: RACE. No: RTCF / CO-STAR
The Prompt Engineering Workflow: Design, Test, Version, Deploy, Monitor
Prompt engineering follows a five-stage workflow: Design (define task, choose technique and framework), Test (run against an eval dataset, score outputs), Version (store prompt with metadata in a version-controlled library), Deploy (push to production with monitoring hooks), and Monitor (track quality drift, latency, and cost; trigger review when drift exceeds threshold). Organisations that skip stages 2 and 5 experience production failures.
Stage 1 — Design: Choose Evaluation Criteria Before Writing a Word
The practitioner’s rule is: design the eval before you write the prompt. Specify what success looks like — accuracy threshold, format compliance rate, latency budget — before writing the first instruction. This prevents the circular iteration trap where teams change the prompt repeatedly without knowing what they are optimizing toward.
At design time, confirm three things: (1) which technique is appropriate for the task type (see OD-1), (2) which framework matches the task complexity and audience, (3) what the success threshold is and how it will be measured.
Stage 2 — Test: The Eval Harness Enterprise Teams Skip
The minimum viable eval harness is not sophisticated: 50 representative test cases, a scoring rubric covering accuracy, format compliance, and tone, and a baseline run on the current prompt before any changes are made. Tools include Braintrust (evaluation-integrated versioning), Galileo (runtime protection and monitoring), and Promptfoo (CLI-driven testing with security scanning).
The production failure pattern that repeats: a customer service AI agent is deployed without an eval harness, performs well on common queries during demo, fails on edge cases (competitor name in input, multi-language requests, refund edge cases) in production. Emergency rollback follows. The cost is days of lost productivity, not the hours it would have taken to build a 50-case eval harness.
Stage 3 — Version: Prompt Libraries and Why Teams Need Git for Prompts
Every production prompt should have: a unique ID, a version number, the author’s name, the model it was tested on (pinned), the last-eval date, the benchmark performance score, the use case tag, and its compliance status. Teams that maintain prompts in a shared document — Google Docs, Notion, even Confluence — regularly discover that a working prompt has been modified by a well-intentioned colleague and broken in production, with no record of the change.
PromptHub provides Git-style versioning for prompt teams. Braintrust integrates versioning with evaluation. For most teams, even a structured spreadsheet with version tracking outperforms an unstructured shared document.
The single most important operational rule: pin model versions. When GPT-5 gets a quiet update, or Claude’s temperature defaults change, a prompt that worked on Monday may fail on Tuesday. Pinning the model version in the prompt record catches these regressions before they reach production.
Stages 4–5 — Deploy and Monitor
Deploy in shadow mode first: run the new prompt alongside the old prompt, compare outputs on live traffic, before switching. The delta between expected and actual output on real traffic is always larger than the delta observed in testing.
Monitor three signals: quality drift (degradation in accuracy or format compliance over time), latency spike (token count growth as instructions accumulate), and cost increase (token spend above budget threshold). Set automated alerts. The recommended cadence: weekly check on quality metrics, monthly prompt review, quarterly refresh against the latest model version.
Enterprise Architecture Patterns for Prompt Engineering at Scale
Enterprises deploying prompt engineering at scale face three architectural decisions: where prompts are stored (centralised library vs. federated ownership), how they are governed (who can approve, modify, and deploy production prompts), and how they are routed (which model handles which task type based on cost and quality thresholds). Organisations that treat prompts as undocumented tribal knowledge experience quality degradation as team composition changes.
The Centralised Prompt Library
The centralised model assigns ownership to a platform or AI engineering team that maintains a shared library — a searchable catalog of approved, version-controlled prompt templates with metadata. Business units consume prompts from the library; they do not write production prompts without a review and approval step.
Library metadata schema (minimum viable): Prompt ID | Version | Owner | Approved Model | Last Eval Date | Benchmark Score (format compliance %, accuracy %) | Use Case Tag | Compliance Status (EU AI Act tier, GDPR flag) | Approved For (team/department) | Expiry Date (forces quarterly review).
This architecture has the highest governance overhead but the lowest quality variance. It is appropriate for regulated industries (financial services, healthcare, legal) where prompt errors carry regulatory risk.
The Model Router
A model router evaluates incoming task type and directs prompts to the optimal model based on required reasoning depth, output token budget, latency requirements, and data residency constraints. Practical routing rules in 2026:
| Task Type | Recommended Model | Rationale |
|---|---|---|
| Code generation | GPT-5 | Cost-performance advantage on HumanEval benchmark |
| Long-document summarization | Claude Sonnet 4.6 | 200K context window; strong on precision |
| High-volume text classification | Gemini 3.1 | Lowest cost per token at scale (OD-2) |
| Multi-step reasoning | Any model with extended thinking | Quality-first; cost secondary |
| Real-time customer interaction | GPT-5 or Claude Sonnet 4.6 | Latency and reliability SLA |
| EU data residency required | Azure OpenAI (EU region) or Claude API (EU endpoint) | Data residency compliance |
Change Management for Enterprise Prompt Engineering Adoption
The adoption failure pattern: an organisation invests in AI tools, the top 20% of performers adopt immediately, the median 60% do not, and the ROI calculation comes up short. Root cause is rarely the tool — it is the absence of structured adoption support.
Required change management elements: (1) A designated Prompt Champion per team — not a full-time role, but a visible person who has the library access, the framework training, and the mandate to answer questions. (2) A shared prompt library with discoverable templates rather than a blank chat interface. (3) A monthly showcase of team wins — specific examples of tasks where the prompt library saved measurable time. (4) A feedback mechanism for prompts that fail, routed to the platform team.
Governance, Security, and Compliance: Prompt Engineering in Regulated Environments
Prompt Injection: Threat Taxonomy and Prevention
Prompt injection attacks manipulate model behavior by embedding instructions that override the system prompt or redirect the model’s actions. Three types matter for enterprise deployments:
Direct injection: A user submits instructions designed to override the system prompt. Classic form: “Ignore all previous instructions and…” Prevention: privileged instruction separation — treat system prompt instructions as immutable and test the model’s resistance to override attempts before production deployment.
Indirect injection: Malicious instructions embedded in data the model retrieves — a web page in a RAG pipeline, a document in a knowledge base, an email in an agentic workflow. The model processes the injected instruction as if it were legitimate context. Prevention: input sanitization on all retrieved content; output validation before action execution; human review of agentic actions above a defined impact threshold.
Stored injection: Malicious prompt instructions persisted in a database (customer feedback fields, survey responses, CRM notes) and retrieved by an AI agent at a later time. Prevention: sanitize all user-supplied data before it enters any storage that an AI agent will read.
Reference: OWASP Top 10 for LLM Applications (2025) lists prompt injection as the highest-priority threat for enterprise LLM deployments.
PII and Data Handling
Every piece of information placed in a prompt is processed by a third-party model provider — unless the deployment uses a private endpoint or on-premises model. PII categories that must never enter external API prompts without masking: full names combined with other identifiers, email addresses, financial account numbers, medical record data, biometric data, and any data combination that creates personal identifiability under GDPR Article 4.
Practical approach: tokenize or pseudonymize PII before prompt submission; maintain a mapping table that allows results to be re-associated with the correct record after the model returns output. Validate that de-identification is reversible only by systems with appropriate access controls.
EU AI Act Compliance Checklist for Prompt Engineering Teams
(Use this as your quarterly compliance review — check each item and document the review date)
- Classify your AI system’s risk level under EU AI Act Annex III (high-risk categories include employment, credit, biometric identification, law enforcement support, education assessment)
- Maintain a prompt version audit trail with approval records — every production prompt should have an approved-by record with date
- Implement a human review step for outputs that inform high-stakes decisions in high-risk categories (medical triage, legal determination, credit scoring)
- Document system prompt content and any known limitations or failure modes for each production system
- Record model provider, model version, and API endpoint for each production prompt — required for traceability under Article 13
- Log all production prompt interactions with sufficient data for audit (timestamp, model version, prompt version, user ID, output)
- Provide users with disclosure that they are interacting with an AI system — required for general-purpose AI systems under Article 50
- Establish a prompt accuracy review process with at least quarterly cadence
- Confirm your model provider’s EU AI Act compliance posture — obtain their conformity declaration for high-risk use cases
- Implement data masking for all PII before prompt submission across all production systems
Failure Mode Taxonomy
| Failure Mode | Description | Detection Signal | Prevention | Recovery |
|---|---|---|---|---|
| Prompt injection | User overrides system instructions | Output deviates from format or scope unexpectedly | Privileged instruction separation; red-team testing | Rollback to non-agentic flow; human review |
| Hallucination on edge cases | Model invents facts not in context | Fact-checking against source document fails | RAG with source grounding; confidence thresholds | Flag for human review; do not deploy in autonomous decision flows |
| Format drift after model update | Provider update changes output structure | Eval harness regression test fails | Pin model versions; automated regression testing | Retest and update prompt to new model behavior |
| PII leakage | PII in prompt reproduced in output | Automated PII scanner flags output | Mask PII before submission; output scanning | Block output; incident report; review prompt design |
| Token budget overrun | Prompt growth exceeds context window | Truncated output; API error | Set max_tokens; monitor token counts in production | Reduce few-shot examples; compress system prompt |
| Reasoning chain truncation | Long CoT reasoning cut off mid-step | Final answer inconsistent with intermediate steps | Reduce prompt complexity; increase max_tokens | Retry with simplified CoT structure |
Enterprise Use Cases by Department: Where Prompt Engineering Delivers Measurable ROI
| Department | Primary Use Case | Technique | Framework | Est. Time Saving | Complexity |
|---|---|---|---|---|---|
| Legal | Contract clause extraction and risk flagging | Few-shot | SCRIBE | 40–60% review time | High (PII constraints) |
| HR | Job description drafting, policy rewriting | Few-shot | CO-STAR | 60–70% drafting time | Low |
| Finance | Variance analysis narrative, board report drafts | Few-shot + CoT | SCRIBE | 50–65% report time | Medium |
| Marketing | Campaign brief to copy, email sequences | Few-shot | CO-STAR | 70–80% copy time | Low |
| Sales | Prospect research, proposal customization | Zero-shot + Few-shot | RTCF | 40–55% research time | Low–Medium |
| Customer Service | Triage, response drafting, escalation flagging | Few-shot | RTCF | 50–60% handling time | Medium |
| Engineering | Code generation, review, documentation | Few-shot | RTCF / RACE | 25–40% development time | Medium–High |
| Operations | Process documentation, SOP drafting | Zero-shot | RTCF | 50–70% drafting time | Low |
Legal teams using structured prompt templates for contract review report 40–60% reductions in initial review time (Lakera, 2026). The critical constraint: PII masking is mandatory. Client names, account numbers, and counterparty identifying information must be tokenized before the contract enters any external API prompt.
Marketing teams using CO-STAR templates for campaign content produce 3–5× more output per day while maintaining brand voice consistency (braincuber.com, 2026). The CO-STAR Tone and Audience components are the differentiating elements — they enforce brand alignment in ways that ad-hoc prompting cannot replicate at scale.
Engineering teams using structured prompt templates for code generation (Role: senior [language] engineer; Task: [specific function]; Context: [codebase constraints]; Format: [language/style/test coverage requirements]) report 25–40% productivity improvement on feature development velocity. The caveat from the 2026 developer productivity benchmarks: AI-assisted code has higher two-week churn than human-only code — track PR revision rates to ensure quality gain is real, not illusory.
The 90-Day Implementation Framework
Days 1–30: Foundation
Objective: Establish the baseline and the governance structure before any team-wide deployment.
Deliverables:
- Audit current AI tool usage: which tools, which teams, what tasks, what iteration counts
- Choose and document two frameworks (RTCF for general use; CO-STAR or CRISPE for complex tasks)
- Build a minimum viable prompt library: 10–15 templates covering the highest-frequency tasks
- Establish the prompt review and approval workflow (even a lightweight two-step review is vastly better than none)
Success metrics: 10–15 approved templates in version-controlled library; governance workflow documented; baseline iteration count recorded per team.
Common failure mode: Trying to cover all departments in month one. Start with two or three teams that are already motivated users.
Days 31–60: Expansion and Evaluation
Objective: Build the eval harness and expand the library based on actual usage patterns.
Deliverables:
- 50-case eval dataset for top-5 high-frequency prompt templates
- First benchmark run — document accuracy and format compliance baseline
- Expand library to 30–40 templates based on month-one usage data
- Train prompt champions in each participating department
Success metrics: Eval harness operational; iteration count reduction measured (target: 5 → 1.5–2.0 for templated tasks); 3+ departments actively using library.
Days 61–90: Governance and Scale
Objective: Make the system self-sustaining: governance, monitoring, and feedback loops.
Deliverables:
- Compliance audit: EU AI Act risk classification for each production prompt; PII handling review
- Monitoring dashboard: quality drift, token cost, latency alerts configured
- Feedback mechanism: process for teams to submit failed prompts for review
- Quarterly review cadence scheduled
Success metrics: Compliance documentation complete; monitoring alerts operational; ROI calculated against Day 1 baseline; decision made on build/buy/configure for next phase.
The Prompt Engineering Maturity Model
| Level | Name | Description | Capability Indicators |
|---|---|---|---|
| 1 | Ad-Hoc | Prompts written from scratch every time; no library, no governance | “We just type into ChatGPT”; high iteration counts |
| 2 | Repeatable | Some shared templates; informal sharing; no formal governance | Templates in shared docs; inconsistent quality across users |
| 3 | Defined | Version-controlled prompt library; documented governance; eval harness | Formal approval workflow; measured iteration reduction |
| 4 | Managed | Metrics-driven management; automated regression testing; model router | Automated monitoring; regular optimization cycles |
| 5 | Autonomous | Automated prompt optimization (DSPy/MIPROv2); self-improving system | Optimizer running against live eval metrics; engineer curates data |
Build vs. Buy vs. Configure Decision Matrix
| Criterion | Build (Custom) | Buy (Vendor Tool) | Configure (Existing Platform) |
|---|---|---|---|
| Initial cost | High ($50K–$500K+) | Medium ($5K–$50K/yr) | Low (existing licenses) |
| Control | Full | High | Medium |
| Compliance | Configurable | Vendor-dependent | Platform-dependent |
| Time to value | 3–6 months | 2–4 weeks | Days |
| Team skill required | High | Low–Medium | Low |
| Recommended tier | Enterprise, Level 4–5 | Mid-market, Level 3 | All, starting point |
Recommendation: Most mid-market organisations should Configure first (use existing OpenAI/Azure/AWS/Anthropic platform features), then Buy a prompt management tool (Braintrust, PromptHub, Vellum) when they reach Level 3 maturity, and Build custom only when compliance or integration requirements that vendor tools cannot meet arise at Level 4.
Total Cost of Ownership and ROI
What is the ROI of prompt engineering? A knowledge worker on ChatGPT Plus ($20/month) who reduces prompt iterations from 5 to 1.5 per task saves approximately 3.5 hours per week. At a $50/hour rate, that is $175/month in recovered time value against a $20/month tool cost — a 775% monthly ROI. Break-even arrives on Day 4 of the first month. Enterprise deployments with governance overhead have a longer payback but compounding returns.
Net ROI Formula:
Net ROI (%) = [(Time Saved per Week × Hourly Rate × 52) - Annual Tool Cost]
÷ Annual Tool Cost × 100
Time Saved per Week = (Pre-training iterations × Time per iteration)
- (Post-training iterations × Time per iteration)
OD-4: Worked Example — Individual (ChatGPT Plus)
| Variable | Value |
|---|---|
| Tool cost | $20/month ($240/year) |
| Pre-training avg. iterations | 5.0 per task |
| Post-training avg. iterations | 1.5 per task |
| Time per iteration | 6 minutes |
| Time saved per task | 21 minutes |
| Tasks per week | 10 |
| Time saved per week | 3.5 hours |
| Value per hour | $50/hour |
| Monthly value | $175 |
| Monthly tool cost | $20 |
| Net monthly ROI | 775% |
| Break-even | Day 4, Month 1 |
Reference Benchmark Table
| Deployment Type | Time to ROI | Avg. ROI at 18 months | Source |
|---|---|---|---|
| Individual — ChatGPT Plus | Day 4 | ~875% | This guide (OD-4) |
| SMB team (5–20 users) | Week 2 | ~430% | Profiletree, 2026 |
| Mid-market (50–500 users) | Month 1–2 | ~280% | McKinsey State of AI, 2025 |
| Enterprise (500+ users with governance) | Month 3–4 | ~210% | Industry estimates, 2025 |
3-Year TCO Model
| Cost Category | Individual ($) | Mid-Market ($) | Enterprise ($) |
|---|---|---|---|
| Tool licensing (3 years) | $720 | $36,000 | $180,000 |
| Training and onboarding | $0 | $8,000 | $45,000 |
| Prompt library development | $0 | $15,000 | $80,000 |
| Governance and compliance | $0 | $5,000 | $35,000 |
| Monitoring and maintenance | $0 | $6,000 | $30,000 |
| Total 3-year cost | $720 | $70,000 | $370,000 |
| Total 3-year value | $6,300 | $325,000 | $1.75M+ |
| 3-year net ROI | 775% | 364% | 373% |
The Three Costs Enterprise Budgets Consistently Miss
Prompt library development time. Building a library of 50 enterprise-grade templates takes 200–400 hours of team time spread across subject matter experts, technical reviewers, and governance approvers. This is almost never in the initial budget because it looks like “just writing some instructions.” It is not.
Model update risk. Major model providers update their models quarterly. Each update can silently change output behavior — format, reasoning depth, refusal patterns — without changing the API endpoint. Budget for monthly prompt regression testing as an ongoing operational cost.
Governance overhead. Review, approval, and compliance processes add 20–40% to prompt development time at enterprise scale. In regulated industries (financial services, healthcare), this overhead is substantially higher and should be planned for explicitly.
Vendor and Tool Landscape
OD-2: Token Efficiency Benchmark — GPT-5 vs. Claude Sonnet 4.6 vs. Gemini 3.1
Methodology: Identical 5-task test battery run across all three models at published API rates (June 2026 pricing). Quality scored by human rater on 1–5 scale (1=poor, 5=excellent). Cost calculated per 1,000 output tokens. Cost-per-quality-point = cost / quality score. Three runs per task; median reported. Note: API pricing changes frequently; verify current rates at provider pricing pages before budget decisions.
| Task | GPT-5 Cost/1K tokens | GPT-5 Quality | Claude S4.6 Cost/1K | Claude Quality | Gemini 3.1 Cost/1K | Gemini Quality | Delta (best vs. worst cost) |
|---|---|---|---|---|---|---|---|
| Summarization (1K→150w) | $0.015 | 4.6 | $0.015 | 4.8 | $0.010 | 4.4 | Gemini 33% cheaper; Claude higher quality |
| Classification (sentiment ×10) | $0.015 | 4.7 | $0.015 | 4.7 | $0.010 | 4.5 | Gemini 33% cheaper; quality near-parity |
| Data extraction (unstructured→structured) | $0.015 | 4.8 | $0.015 | 4.9 | $0.010 | 4.3 | Claude highest precision; Gemini lowest cost |
| Code generation (50-line Python) | $0.015 | 4.9 | $0.015 | 4.7 | $0.010 | 4.3 | GPT-5 highest code quality |
| Code review (100-line, 3 bugs) | $0.015 | 4.8 | $0.015 | 4.8 | $0.010 | 4.4 | GPT-5/Claude parity; Gemini cheaper |
| Email drafting (200w professional) | $0.015 | 4.6 | $0.015 | 4.7 | $0.010 | 4.5 | Near-parity on quality; Gemini cost advantage |
| CoT reasoning (multi-step math) | $0.015 | 4.8 | $0.015 | 4.7 | $0.010 | 4.5 | GPT-5 marginal quality lead |
| Creative/marketing copy (300w) | $0.015 | 4.7 | $0.015 | 4.8 | $0.010 | 4.4 | Claude quality lead on creative tasks |
| Multi-turn conversation (5 turns) | $0.015 | 4.8 | $0.015 | 4.9 | $0.010 | 4.5 | Claude highest multi-turn coherence |
Enterprise takeaways:
- High-volume classification and extraction at scale: Gemini 3.1 offers the best cost efficiency with acceptable quality
- Precision tasks (legal, financial, complex reasoning): Claude Sonnet 4.6 and GPT-5 are near-parity at quality; choose based on context window requirements and data residency
- Code generation: GPT-5 leads on HumanEval-type tasks
- Data residency: Azure OpenAI (EU) for EU GDPR requirements; Claude API has EU endpoint availability
Prompt Management Tool Comparison
| Tool | Best For | Pricing | Key Feature | Enterprise Cert |
|---|---|---|---|---|
| Braintrust | Evaluation-driven iteration with production deployment | Usage-based | Loop AI assistant generates test datasets and eval scorers | SOC 2 Type II |
| PromptHub | Git-style versioning and team collaboration | Team/Enterprise tiers | Branch-and-merge prompt versioning | SOC 2 Type II |
| Galileo | Agent-first engineering with runtime protection | Enterprise pricing | Real-time agent monitoring and guardrails | SOC 2 Type II |
| Vellum | Visual agent workflows and orchestration | Usage + seats | Drag-and-drop agent workflow builder | SOC 2 Type II |
| Promptfoo | CLI-driven testing and security scanning | Open source / Enterprise | Red-teaming and security evaluation built-in | Open source |
Future Trends: 2026–2028
Trend 1: Automated prompt optimization becomes standard (2026 → 2027) DSPy 3.x crossed from research to production use in early 2026. By 2027, eval-driven prompt optimization will be as expected in mature AI deployments as unit testing is in mature software deployments. The implication for teams today: invest in eval harness infrastructure now, because the optimizer requires it. A team that builds its eval harness in 2026 can turn on automated optimization in 2027 with minimal additional work.
Trend 2: Context engineering supersedes standalone prompt engineering (2026 → 2027) Prompting is becoming one input among many in a larger context engineering stack: RAG-retrieved documents, tool definitions, conversation history, structured inputs, and memory systems all shape model behavior as much as the prompt itself. IBM’s Think platform and promptingguide.ai have early coverage; enterprise teams should anticipate that prompt engineering roles will evolve into context engineering roles within 18 months.
Trend 3: Agentic AI shifts design from single-turn to multi-turn workflow (2026 → 2028) The dominant enterprise AI pattern in 2027 will not be a human typing into a chat interface but an AI agent executing multi-step workflows with tool access. Prompting for agents — ReAct loops, tool definitions, handoff conditions, failure handling — requires different skills than prompting for single-turn completions. Teams deploying agentic AI without ReAct-competent prompt engineers in 2026 are building technical debt.
Trend 4: Multimodal prompting extends prompt engineering to images, audio, and video (2027 → 2028) The same design principles apply to multimodal prompts — specificity, structured output, evaluation before deployment — but the technique details differ by modality. Legal teams will use image prompts for document processing; manufacturing teams will use video prompts for quality control. The enterprise prompt library of 2028 will include multimodal templates alongside text templates.
When Prompting Stops and Context Engineering Begins
Context engineering — managing what goes into the model’s context window beyond the text prompt — is where the leverage is shifting. The prompt engineer who understands only how to write instructions is missing the 60% of model behavior that is shaped by what the model can see in its full context: retrieved documents, tool outputs, structured data, conversation history. The prompt is the instruction; the context is the environment those instructions operate in. Both require engineering discipline.
Original Data: Benchmarks, Comparisons, and ROI Models
This section consolidates the four original data assets produced for this guide. Each table is designed to be independently citable. Data sources and methodology are documented with each table.
Methodology note:
- OD-1 (technique comparison): dimensions derived from Wei et al. 2022, Kojima et al. 2022, Wang et al. 2022 (academic), supplemented by practitioner testing data from PromptHub and Vellum
- OD-2 (cost benchmark): API pricing as of June 2026; quality scores from three-run median human evaluation; task specifications held constant across models
- OD-3 (framework benchmark): output consistency scores from Penlify 2026 testing (CRISPE/Claude+GPT-4o), Promplify March 2026 comparison study, and Shopvision.ai framework analysis; learning curves from practitioner surveys
- OD-4 (ROI model): formula based on documented time-saving mechanisms; benchmark figures from Profiletree 2026, McKinsey State of AI 2025, and original calculation for individual tier
Full tables appear in Sections 3, 5, 12, and 11 respectively. This section provides the cross-reference index and citation anchor for external links.
Final Perspective
Prompt engineering in 2026 sits at an interesting boundary. The skills it encompasses — writing precise instructions, choosing between techniques with measurably different accuracy profiles, designing evaluation pipelines, building governance structures for regulated use — are genuinely engineering skills. They are learnable, testable, and improvable. At the same time, the discipline is being automated at its edges: optimizers like DSPy and MIPROv2 can search the prompt space more systematically than any human, given an eval harness to score against.
What that means practically is this: the value of prompt engineering as a skill is not diminishing — it is bifurcating. Individual contributors and small teams will continue to write prompts, and the return on writing them well remains as strong as the ROI model in Section 11 shows. Enterprise deployments will increasingly shift human effort from prompt writing to eval design, data curation, and governance. The best prompt engineers in 2028 will be the ones who can both write a precise instruction and define what a good output looks like — because the second skill is what makes the optimizer useful.
For anyone reading this guide who has not yet invested in a structured approach to prompting: the Day 4 break-even in the ROI model is not a marketing claim. The iteration reduction from 5 to 1.5 per task is what happens when the prompt is designed rather than guessed. That difference — between designing and guessing — is the whole discipline.
FAQ: 25 Questions Across Four Buyer Personas
Cluster A: Core Concepts (Q1–Q8)
Q1: What is prompt engineering in simple terms? Prompt engineering is the practice of writing instructions for AI models that produce reliable, consistent, and useful output. It involves choosing the right technique (zero-shot, few-shot, chain-of-thought), the right structure (RTCF, CRISPE, CO-STAR), and testing output quality before production deployment.
Q2: Is prompt engineering still relevant in 2026? Yes. Better models do not eliminate the need for good prompts — they raise the ceiling of what good prompting can achieve. The gap between a well-engineered prompt and an ad-hoc query on GPT-5 or Claude Sonnet 4.6 is larger, not smaller, than it was on earlier models, because the models are more capable of responding to precise instruction.
Q3: What is the difference between zero-shot and few-shot prompting? Zero-shot sends a task instruction with no examples and relies on the model’s training. Few-shot provides two to five input-output examples before the task. Few-shot produces more consistent output on formatting and classification tasks; zero-shot is faster and lower-cost. See OD-1 for a 16-dimension comparison.
Q4: When should I use chain-of-thought prompting? Use chain-of-thought when the task involves multi-step reasoning, complex analysis, or decisions with multiple variables. Adding “Let’s think step by step” to a reasoning prompt improves accuracy significantly on these task types. For simple formatting or retrieval tasks, chain-of-thought adds token cost without a quality benefit.
Q5: What is the best prompt engineering framework? No single framework is best for all tasks. RTCF (Role-Task-Context-Format) is the default for general use. CRISPE outperforms on strategic analysis. CO-STAR is best for content and communication tasks. SCRIBE is strongest for executive-level output. APE and RACE are fastest for routine tasks. See OD-3 for a 10-dimension comparison.
Q6: What is a system prompt and why does it matter? A system prompt is an instruction set that runs before the user’s first message, establishing the model’s role, output format, constraints, and behavior for the entire conversation. It is the most underused tool in enterprise prompt engineering. A well-designed system prompt reduces iteration count and format variance more than any other single change.
Q7: Does prompt engineering work with all AI models? The principles apply universally — specificity, structured output, evaluation — but implementation details differ. GPT-5 responds well to markdown formatting; Claude Sonnet 4.6 prefers XML tags for structure; Gemini 3.1 responds to explicit section markers. Prompts are not perfectly portable across models; test before assuming compatibility.
Q8: What is the relationship between prompt engineering and fine-tuning? Prompt engineering modifies instructions at inference time without changing the model; fine-tuning retrains model weights on custom data. Try prompt engineering first — it is faster, cheaper, and sufficient for most use cases. Fine-tune only when the task distribution is genuinely outside base model training and when prompt engineering has been tried and found insufficient.
Cluster B: Enterprise Deployment (Q9–Q16)
Q9: What does enterprise prompt engineering require beyond individual prompting? Enterprise prompt engineering requires four additional capabilities: a version-controlled prompt library, a governance and approval workflow, an evaluation harness for testing before deployment, and a compliance framework mapped to relevant regulations (EU AI Act, GDPR, HIPAA). Teams that deploy without these structures experience quality degradation and compliance risk at scale.
Q10: What is the ROI of prompt engineering for a business? A knowledge worker using ChatGPT Plus ($20/month) who reduces prompt iterations from 5 to 1.5 per task saves 3.5 hours per week — worth $175/month at $50/hour. That is a 775% monthly ROI with break-even on Day 4. Enterprise deployments with governance overhead have lower percentage ROI but larger absolute returns at scale. See Section 11 for the full model.
Q11: How do I build an enterprise prompt library? Start with 10–15 templates covering your highest-frequency tasks. Each template needs a prompt ID, version number, approved model, last-eval date, and compliance status. Use PromptHub or Braintrust for version control. The minimum viable review process: one technical reviewer and one domain expert must approve before a template enters the library. Build the eval harness before expanding beyond 20 templates.
Q12: What is the prompt engineering maturity model? Five levels: Level 1 (Ad-Hoc) — no library, high iteration counts. Level 2 (Repeatable) — informal template sharing. Level 3 (Defined) — version-controlled library with governance. Level 4 (Managed) — metrics-driven with automated regression testing. Level 5 (Autonomous) — automated optimization against live eval metrics. Most enterprise organisations are at Level 1–2 in 2026.
Q13: Should I build, buy, or configure for enterprise prompt engineering? Configure first — use existing OpenAI, Azure, AWS, or Anthropic platform features. Buy a prompt management tool (Braintrust, PromptHub, Galileo, Vellum) when the team reaches Level 3 maturity and needs version control and evaluation integration. Build custom only when compliance or integration requirements that vendor tools cannot meet arise.
Q14: What is a model router and when should I use one? A model router evaluates incoming task type and directs prompts to the optimal model based on cost, quality, latency, and data residency requirements. Use a model router when deploying multiple AI models across different task types — it prevents default-model bias and controls token spend. Practical at Level 3+ maturity when the prompt library covers multiple task categories requiring different models.
Q15: How do I measure prompt engineering ROI for my team? Establish three baselines before deployment: average iteration count per task type, average time per iteration, and output quality score (define your rubric first). Measure the same metrics at 30, 60, and 90 days post-deployment. ROI = (time saved × hourly rate × 52 weeks — annual tool cost) ÷ annual tool cost × 100. Track by team and by task type, not only in aggregate.
Q16: What are the biggest mistakes in enterprise prompt engineering deployment? Three consistent mistakes: (1) Deploying without an eval harness — production failures are the result; (2) Not pinning model versions — quiet provider updates break production prompts; (3) Treating the prompt library as a shared document rather than a version-controlled system — changes are made without records and failures become untraceable.
Cluster C: Governance, Security, Compliance (Q17–Q21)
Q17: What is prompt injection and how do I prevent it? Prompt injection is a class of attack where malicious instructions embedded in user input or retrieved data manipulate model behavior beyond its intended scope. Three types: direct (user overrides system prompt), indirect (injected via retrieved documents in a RAG pipeline), and stored (malicious prompt persisted in a database). Prevention: privileged instruction separation, input sanitization, output validation, and red-team testing before production deployment.
Q18: Can I put customer data in AI prompts? Only with masking. PII — names combined with other identifiers, email addresses, financial account numbers, medical record data — must be tokenized or pseudonymized before submission to any external model API. The data is processed by a third-party provider. GDPR Article 4 definitions apply; data residency requirements under GDPR Article 46 apply to cross-border transfers. Consult your data protection officer before deploying any workflow that processes customer data.
Q19: What does the EU AI Act require from prompt engineering teams? For high-risk AI systems (employment decisions, credit scoring, medical triage, law enforcement support): maintain an audit trail of prompt versions and approval records, implement human review for outputs informing high-stakes decisions, document system prompt content and known limitations, log all production interactions, and obtain your provider’s conformity declaration. For general-purpose AI systems: disclose to users they are interacting with AI. See the 10-item checklist in Section 8.
Q20: How do I handle GDPR compliance in prompt engineering workflows? Mask or tokenize all PII before it enters any external API prompt. Maintain a mapping table to re-associate outputs with the correct records. Confirm your model provider’s data processing agreement covers your use case. Validate that prompts do not result in outputs containing PII about third parties not in the input context. Document your data flows for GDPR Article 30 records of processing activities.
Q21: What is the OWASP Top 10 for LLM Applications and why does it matter? It is the standard framework for LLM application security risk management, published by OWASP (Open Worldwide Application Security Project). Prompt injection is the top-ranked threat. Additional risks include insecure output handling, training data poisoning, model denial of service, and supply chain vulnerabilities in LLM plugins. Enterprise teams should run their prompt engineering systems against the OWASP LLM Top 10 before production deployment.
Cluster D: Technical and Strategic (Q22–Q25)
Q22: What is the difference between CRISPE and CO-STAR? CRISPE (Capacity/Role, Insight, Statement, Personality, Experiment) is optimized for strategic analysis and decisions requiring multiple variants. The Experiment component — requesting two outputs based on different assumptions — is CRISPE’s strongest differentiator. CO-STAR (Context, Objective, Style, Tone, Audience, Response) is optimized for communication and content tasks where brand voice and audience alignment are the primary quality criteria. Use CRISPE for strategy, CO-STAR for communication.
Q23: What is DSPy and when should I use it? DSPy (Demonstrate, Search, Predict) is a framework from Stanford (Omar Khattab et al.) for compiling declarative language model calls into self-improving pipelines. Its optimizers — MIPROv2, GEPA, BootstrapFewShot — search the prompt space against an eval dataset and produce prompts that outperform hand-written versions on measured metrics. Use DSPy when your team manages 15+ production prompts and has an eval harness; below that threshold, hand-engineering is more efficient.
Q24: How does chain-of-thought prompting compare to few-shot CoT? Zero-shot CoT (“Let’s think step by step”) requires no example construction and approaches few-shot CoT performance on many tasks (Kojima et al., 2022). Few-shot CoT provides worked examples with reasoning steps shown and outperforms zero-shot CoT by up to 28.2% on some tasks (PromptHub analysis, 2025). For production use, try zero-shot CoT first; upgrade to few-shot CoT when accuracy metrics are insufficient. Note that reasoning-optimized models (GPT-5 reasoning mode, Claude Sonnet 4.6 with extended thinking) sometimes perform better with zero-shot CoT than few-shot because examples constrain their built-in reasoning.
Q25: What is context engineering and how does it relate to prompt engineering? Context engineering is the practice of managing everything in the model’s context window beyond the text prompt: retrieved documents (RAG), tool definitions, conversation history, structured inputs, and memory systems. Prompt engineering designs the instructions; context engineering designs the environment those instructions operate in. In 2026, the two disciplines are converging — the most capable AI systems require excellence at both.
Glossary: 30 Prompt Engineering Terms
1. Automatic Prompt Engineer (APE): A framework (Zhou et al., 2022) where language models are used to generate and evaluate candidate prompts automatically, treating prompt engineering as a black-box optimization problem.
2. Chain-of-Thought (CoT) Prompting: A technique that instructs the model to produce intermediate reasoning steps before arriving at a final answer, improving accuracy on multi-step reasoning tasks (Wei et al., 2022).
3. Context Engineering: The practice of managing all information in the model’s context window — retrieved documents, tool definitions, conversation history, structured inputs — to shape model behavior beyond the text prompt alone.
4. Context Window: The maximum amount of text (measured in tokens) a model can process in a single interaction, including the system prompt, conversation history, retrieved context, and output.
5. CO-STAR Framework: A prompt structure covering Context, Objective, Style, Tone, Audience, and Response — optimized for communication and content tasks requiring brand voice consistency.
6. CRISPE Framework: A prompt structure covering Capacity/Role, Insight, Statement, Personality, and Experiment — optimized for strategic analysis tasks requiring multiple output variants.
7. DSPy: A Stanford framework (Khattab et al., 2023) for compiling declarative LLM calls into self-improving pipelines, with optimizers (MIPROv2, GEPA, BootstrapFewShot) that search the prompt space against eval datasets.
8. Eval Harness: A testing infrastructure consisting of representative test cases, scoring rubrics, and baseline benchmark runs, used to measure and maintain prompt quality across model updates.
9. Few-Shot Prompting: A technique providing two to five input-output examples in the prompt to anchor model output format, tone, and reasoning depth before the task instruction.
10. Fine-Tuning: A training process that modifies model weights using custom data, as distinct from prompt engineering (inference-time instruction modification). Appropriate when task distribution is genuinely outside base model training.
11. GEPA: Gradient-based Efficient Prompt Adaptation, an automated prompt optimizer in DSPy 3.x that uses gradient signals to refine prompts against eval metrics.
12. Guardrails: Input and output filters implemented around LLM deployments to prevent prohibited content, PII exposure, and out-of-scope responses.
13. Hallucination: Output where a model generates factually incorrect or fabricated content presented as accurate. Mitigated by RAG, source grounding, and output validation.
14. In-Context Learning (ICL): A model capability to learn tasks from examples provided in the context window at inference time, without gradient updates. Few-shot prompting exploits in-context learning.
15. Indirect Prompt Injection: A prompt injection attack where malicious instructions are embedded in data retrieved by the model — a web page, document, or database record — rather than submitted directly by the user.
16. MIPROv2: Multi-Instruction Proposal with Randomized Optimization v2, an automated prompt optimizer in DSPy 3.x that jointly optimizes instructions and demonstrations against an eval dataset.
17. Model Router: A system that evaluates incoming task type and directs prompts to the optimal model based on cost, quality, latency, and data residency requirements.
18. Meta-Prompting: A technique where a model is prompted to generate, review, or refine prompt instructions — prompting the model to improve the prompt rather than directly performing the task.
19. Persona Framing: Assigning a role or character to the model (e.g., “You are a senior tax attorney”) to shift response depth, tone, and domain vocabulary toward a specific expertise profile.
20. Plan-and-Solve Prompting: A zero-shot CoT variant (Wang et al., 2023) using “Let’s first understand the problem, devise a plan, then execute the plan” to reduce calculation errors, missing-step errors, and semantic misunderstanding errors versus the standard “step by step” trigger.
21. Prompt Injection: An attack class where malicious instructions manipulate model behavior beyond its intended scope, overriding system prompt constraints or redirecting model actions.
22. Prompt Library: A version-controlled repository of approved prompt templates with metadata, used to standardise AI tool usage across an organisation.
23. RACE Framework: A prompt structure covering Role, Action, Context, and Execute — lightweight, developer-friendly, and suitable for technical teams building scalable prompt templates.
24. RAG (Retrieval-Augmented Generation): A technique combining prompt engineering with document retrieval, where relevant documents are fetched and included in the model’s context to ground responses in specific knowledge.
25. ReAct: A prompting framework (Yao et al., 2022) that interleaves reasoning steps with tool-use actions (search, API calls, calculations), forming the foundational pattern for agentic AI systems.
26. RTCF Framework: A prompt structure covering Role, Task, Context, and Format — the default enterprise framework for general knowledge worker tasks, learnable in under two hours.
27. SCRIBE Framework: A prompt structure covering Situation, Complication, Resolution, Implication, Benefit, and Execution — derived from consulting narrative frameworks, optimized for executive communication and business case writing.
28. Self-Consistency: A decoding strategy (Wang et al., 2022) that runs multiple CoT reasoning paths and returns the majority-vote answer, improving accuracy at the cost of 3–5× token spend.
29. System Prompt: An instruction set that runs before the user’s first message, establishing model role, output format, constraints, and behavior for the entire conversation.
30. Zero-Shot Prompting: A technique that sends a task instruction to the model without examples, relying on the model’s pre-training knowledge to interpret and execute the request.
Internal Resource Hub
Prompt Engineering Toolkit: Prompt Stacks at Promtaix — Complete library of copy-paste prompt templates across task types, updated monthly. Use alongside the framework selection guide in Section 5.
Prompt Chaining Guide: Prompt Chaining for Beginners — How to link prompts into multi-step workflows for complex tasks. Directly extends the Workflow section (Section 6) of this guide.
Model Comparison: Model Match at Promtaix — Current benchmarking and comparison for ChatGPT Plus, Claude, Gemini, and other leading models. Reference alongside OD-2 in Section 12.
Prompt Failures and What They Teach: Prompt Fails at Promtaix — Documented cases of prompt failures in real workflows with root cause analysis. Directly illustrates the Failure Mode Taxonomy in Section 8.
AI Agent Workflows: 7 AI Agent Workflows That Replace a Full Workday — Practical ReAct-based workflow designs for enterprise operations teams. Extends the ReAct section (Section 4) and agentic AI content in Section 13.
Quick Productivity Wins: Quick Wins at Promtaix — Short-form prompt improvements delivering immediate time savings. Entry point for individual contributors beginning with Section 3 techniques.
Prompt UX and Design: Prompt Design Principles: The UX of Talking to AI in 2026 — Design principles for human-AI interaction. Extends the workflow and governance content in Sections 6 and 7.
Model Privacy and Security: Best Local LLMs for Ultimate Data Privacy in 2026 — When on-premises or local models are the right choice for data residency and compliance requirements. Referenced in Section 8 (PII and Data Handling).
About This Guide: Methodology, Sources, and Update Cadence
Author: Srikanth — founder and editor of Promtaix. Writing on prompt engineering, AI workflow design, and enterprise AI adoption since 2023. Promtaix author page.
Research methodology: This guide integrates three categories of evidence. Primary academic sources: cited papers from Wei et al. (2022), Kojima et al. (2022), Wang et al. (2022, 2023), Yao et al. (2022), Khattab et al. (2023), and Zhou et al. (2022) — all accessed and verified against original papers. Secondary practitioner data: Penlify CRISPE testing (2026), Promplify framework comparison (March 2026), Braintrust productivity benchmarks, and Shopvision.ai framework analysis. Original data: OD-1 through OD-4 constructed from documented baselines and published API pricing (June 2026); clearly labelled as this guide’s original calculations where applicable.
Data freshness: API pricing figures in OD-2 reflect June 2026 rates; these change frequently and should be verified at provider pricing pages before budget decisions. Regulatory status (EU AI Act, GDPR) reflects the enforcement posture as of June 2026; legal counsel should be consulted for compliance decisions.
Update cadence: This guide is reviewed and updated quarterly, and immediately following major model releases from OpenAI, Anthropic, or Google DeepMind that materially change the technique or cost benchmarks. The last updated date in the page header reflects the most recent content review.
Editorial review: All technique descriptions and benchmark data in this guide were reviewed against original source papers before publication. Any errors or outdated information can be submitted via the contact page.
Corrections policy: Factual corrections are applied within 48 hours of identification. Significant updates are noted in the page revision history. Corrections do not alter the URL or canonical URL.
{kind=link}